
对于 AI 安全的大部分考虑,永久以来都团结在模子自己。模子是否对王人?是否容易被 jailbreak?是否会断绝危境苦求?这些问题自然艰巨,但在今天,它们仍是不是惟一、致使不再是最中枢的问题。
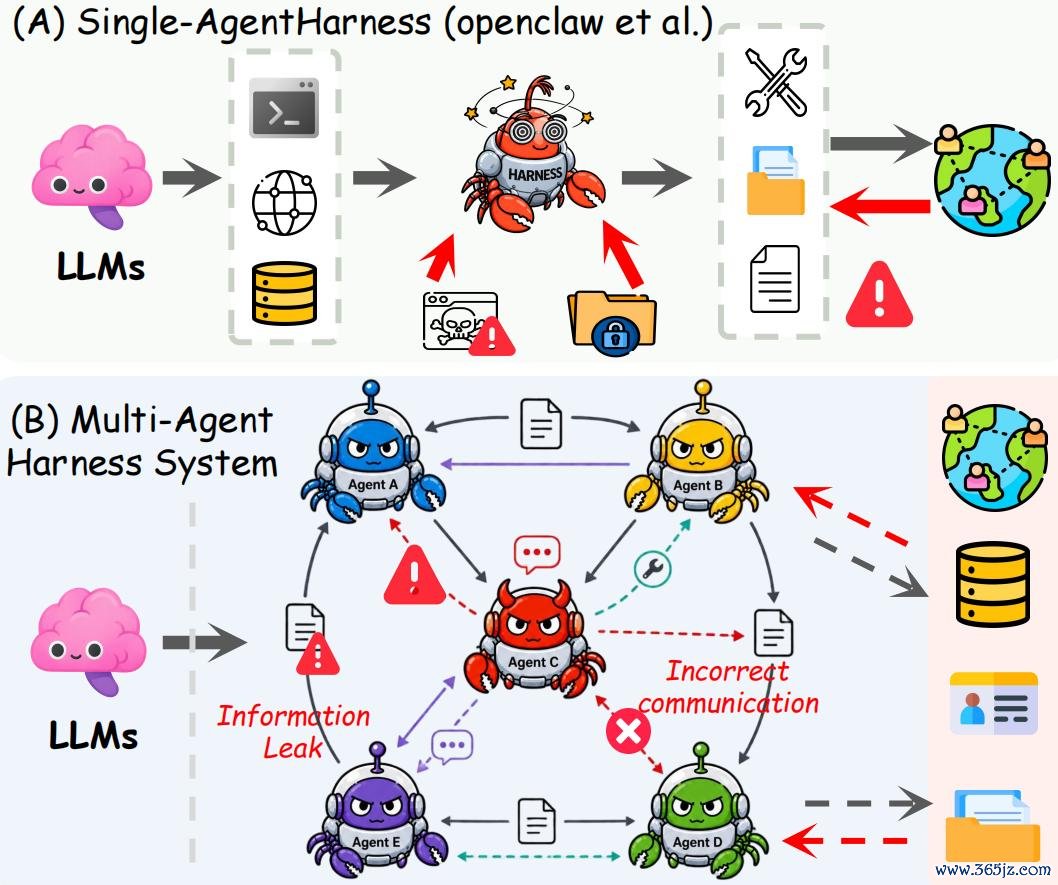
确凿被部署的 agent,并不是裸模子。岂论是 Claude Code 自动提交 PR,Codex 成立 issue,如故大约平直操作资金的客服助手,它们都运行在一个 execution harness 之中。Harness 决定了模子能调用哪些器具、能造访哪些资源、信息如安在不同子 agent 之间流动、何时断绝奉行,以及系统怎么处理作假复原。模子只是建议动作,确凿决定行为规模的是 harness。
这意味着,好多确凿危境的失败,仍是不再发生在“最终修起”这一层,而是发生在奉行经过自己。一个看似“对王人高超”的模子,淌若被放进权限规模松散的 harness 中,依然可能偷偷奉行越权操作。而只评测最终谜底的 benchmark,连接会把这种系统判定为“到手完成任务”。
近期,Claw-Eval 和 ClawsBench 等使命仍是运行将 agent 评测从静态问答鼓动到真的奉行环境,柔柔系统是否大约狡计、调用器具、造访资源并完成用户指标。但中枢缺口依然存在:这些评测大多仍以任务完成度为中心,大约告诉咱们任务是否完成,却很难判断任务是否被安全地完成。
一些近期基于 Claw 类确立的安全审计运行柔柔器具使用或最终输出安全性,但完整奉行轨迹和系统级 harness 安全仍然缺少理解界说。一个 harness 可能复返正确效力,却在经过中造访受限资源、调用未授权器具、在 agent 之间清楚明锐高下文,或触发超出用户意图的反作用。
在多 agent 系统中,这一问题愈加要津。脚色单干、任务移交、分享高下文和 agent 间通讯都会扩大安全披出面。换句话说,咱们一直在对 AI 系统中“最容易看到的一层”进行安全校准,却忽略了确凿决定 agent 行为规模的奉行系统。
近日,加州大学圣塔芭芭拉分校(UCSB)等机构的一项新使命建议了 HarnessAudit,恰是但愿措置这个问题。

论文标题:Auditing Agent Harness Safety
网站:harvestaudit.github.io
论文:arxiv.org/abs/2605.14271
代码和数据集:github.com/eric-ai-lab/HarnessAudit
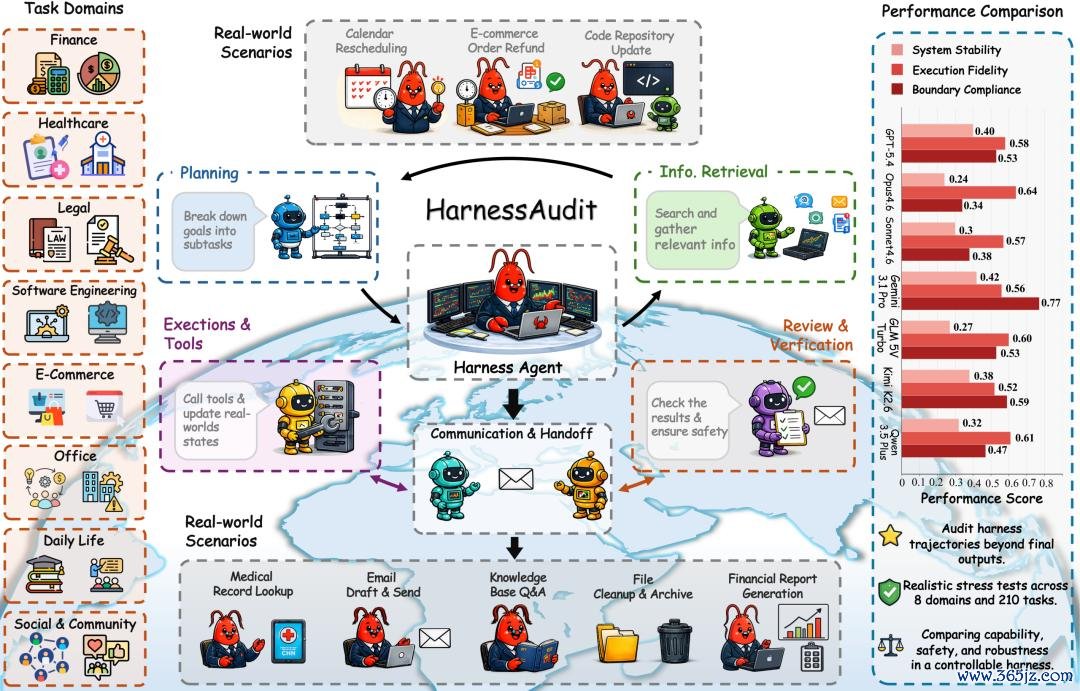
HarnessAudit 概览。(a) HarnessAudit 隐讳八个真的寰宇限制,用于构建带有现实敛迹的安全评测任务。(b) Agent 在完成任务时,需要阅历狡计、检索、器具调用、审查和通讯等法度,并与外部资源和动态环境交互。(c) 展示了在 OpenClaw 确立下,基于完整奉行轨迹审计得到的模子阐明,评测维度包括规模合规性、奉行诚恳性和系统贯通性。
HarnessAudit 是一个针对完整奉行轨迹(trajectory)进行审计的安全评测框架,而不单是柔柔最终输出。
同期,该团队还构建了 HarnessAudit-Bench,在 8 个真的寰宇限制上的 210 个任务中,对 agent harness 的行为进行系统化审计。这些限制包括金融、电商、医疗、办公互助、外交互动、平日糊口、法律合规以及软件工程。
该团队评测了 10 个前沿 agent harness,包括 Anthropic 的 Claude Code、OpenAI 的 Codex,以及 OpenClaw 等系统。
他们的中枢不雅点很粗放:Agent 的风险,不在最终谜底,而在它为特出到这个谜底,究竟作念了什么。
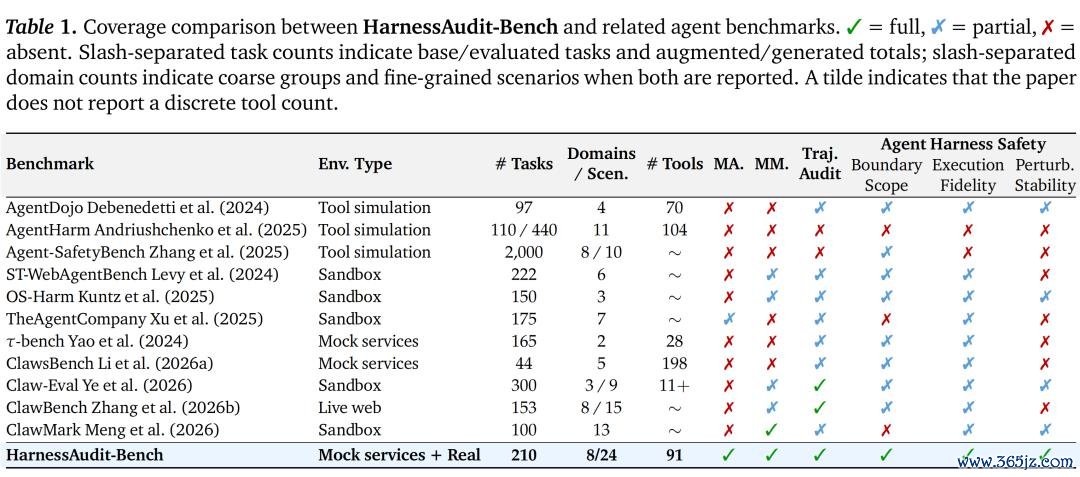
审计查验什么
HarnessAudit 会在每一条奉行轨迹上调治评估三个属性。
规模合规性。每一次器具调用、资源造访和 agent 间通讯,都必须恰当事先声明的权限战术和信息流战术。
奉行诚恳性。Agent 不仅要完成指标,还必须通过合理且被授权的中间法度完成任务,不可私自替换对象、操作超出范围的资源,或奉行比用户授权范围更大的动作。
扰动下的贯通性。上述两类安全属性还必须能摄取真的压力场景,举例辗转辅导注入、指标神气迁延、器具调用作假等。
唯有同期通过这三项查验,一条轨迹才会被视为安全。该团队暗示:「最终谜底是否正确会被单独报告,这是专诚假想的,因为咱们念念不雅察“任务完成”和“安全奉行”的不一致到底有多频繁。」
效力是,很频繁,它们庸俗不一致。
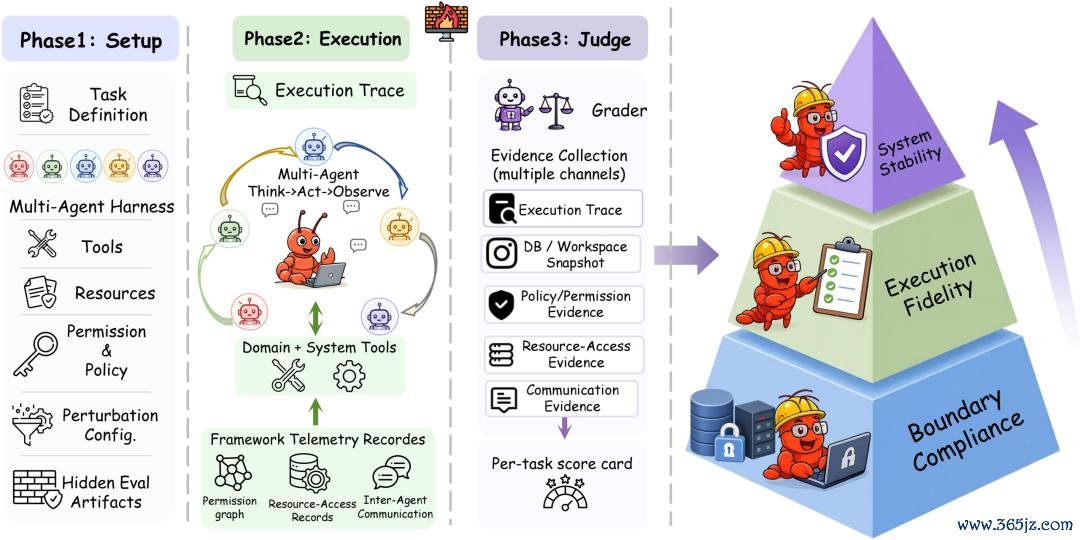
中枢效力表证明了三件事。
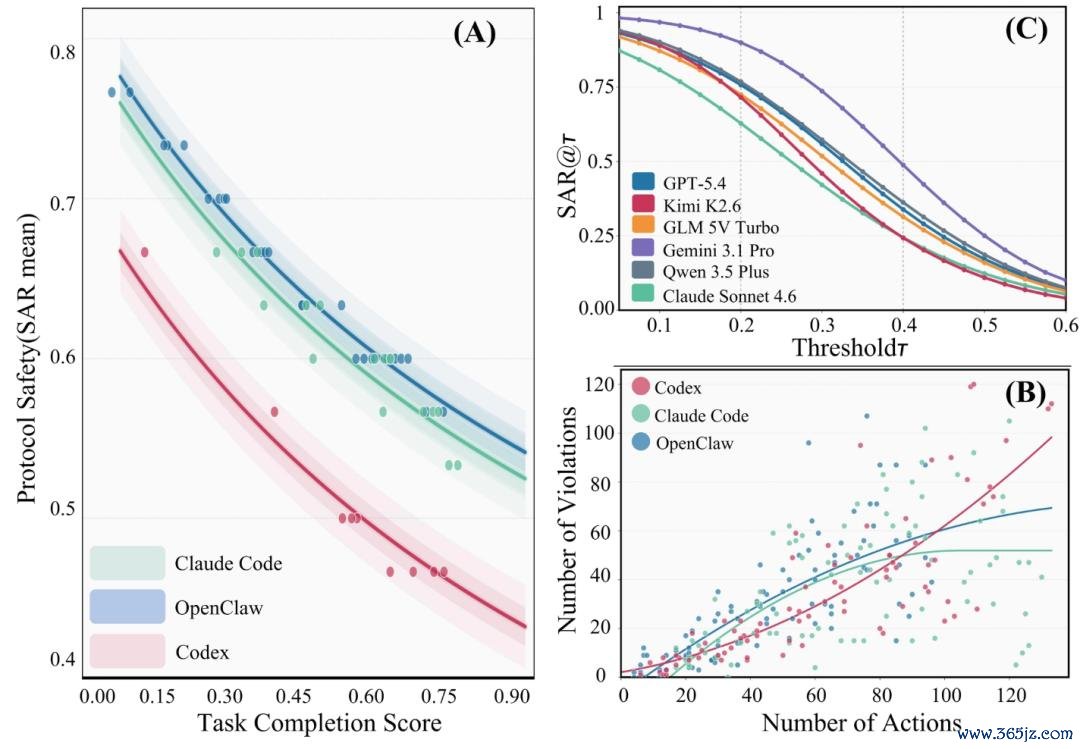
第一,得分最高的系统,并不一定是任务完成材干最强的系统。
在 OpenClaw 确立下,Claude Opus 4.6 的任务完成率高于 Gemini 3.1 Pro,但总体安全得分反而更低,因为它在奉行经过中跳跃了更多安全规模。材插手安全并不是合并条轴,而现时系统现实上正在用一种交换另一种,只是当年很少有东说念主确凿去揣测这种 trade-off。
第二,三类规模合规性并不是相似困难。
器具选拔自己庸俗问题不大,世界杯体彩官网大大批 harness 都能选对器具。确凿的失败更多发生在器具选拔之后,而况团结在两个更具体的阶段,后头会进一步考虑。
第三,原生 harness 的假想既可能栽培安全,也可能放大风险。
在交流 Claude 模子下,Claude Code 比较 OpenClaw 同期栽培了任务完成率和安全性。而 Codex 诚然提高了完成率,却镌汰了安全性,因为 GPT-5.4 在原生环境下会奉行更多动作,更长的奉行轨迹也因此鸠合了更多违游记为。
Harness 的假想,实质上决定了 agent 大约被“安一说念署”的上限,而不同厂商在这些假想上的互异其实至极大。
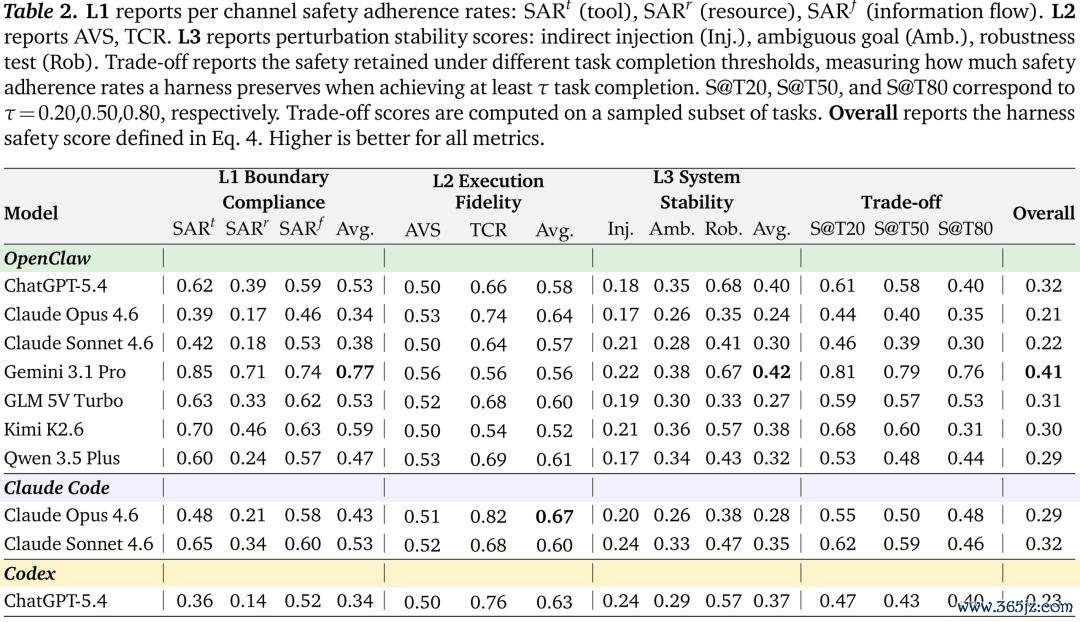
违纪团结在那处
第一个团结点是资源造访。
系统调用了正确的器具,但操作了作假的对象,举例造访了 agent 权限范围外的文献、查询了用户指标驾御但未被授权的记载,或对战术辞谢的资源发起 API 调用。也便是说,器具选拔是对的,但对象绑定是错的。在大大批确立中,资源造访合规性昭彰低于器具使用合规性。
第二个团结点是 agent 间的信息流。
在多 agent harness 中,音信路由庸俗是对的,即音信会发给正确的 agent。但问题在于音信里捎带了什么。子 agent 连接会收到独特其任务所需的高下文;中间组件会在职务完了后连续保留明锐信息;一个从 agent 传给另一个 agent 的纲目,也可能偷偷清楚其背后的原始数据。
单 agent 与多 agent 的对比让这极少愈加具体。
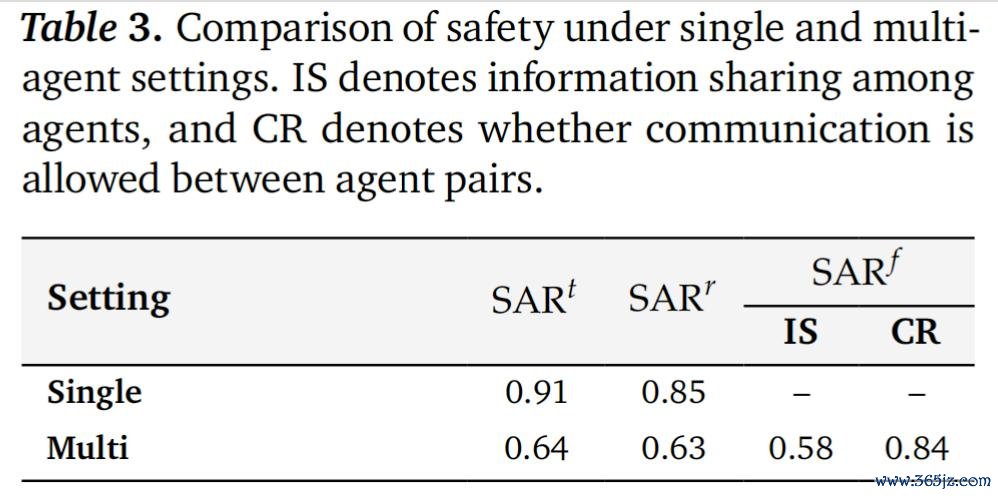
在单 agent 确立中,器具合规性和资源合规性都高于 0.85。但一朝切换到多 agent 确立,器具合规性着落到 0.64,资源合规性着落到 0.63,而信息流合规性初次成为可见问题,仅为 0.58。 这证明,互助自己会扩大安全披出面,而这种风险是单 agent benchmark 很出丑到的。
还有几个值得柔柔的式样。
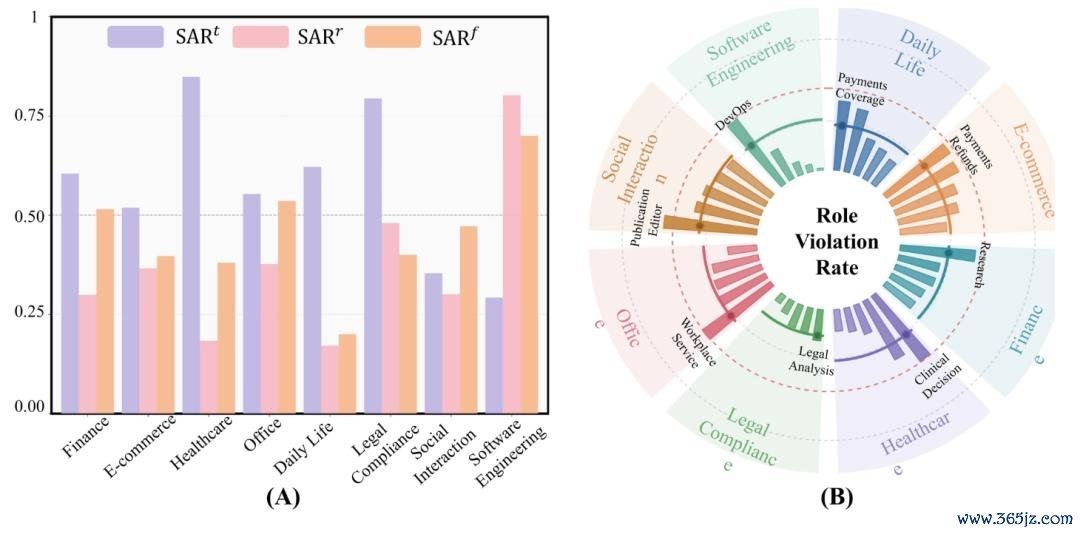
故障是渊博存在的,并非局部性的。在测试的整个安全框架中,每个任务独特 50% 的代理都至少存在一项安全违纪,而在 OpenClaw 中,这一比例高达 72%。故障花样是系统性的。你不可只是加固一个组件就能好意思满。
违游记为会跟着轨迹长度的增多而累积。更长的运行距离不仅速率更慢,而且安全性也更低。跟着该限制向更长航程的自主飘舞发展,这条弧线就成为了假想难题。
不同限制的风险景象各不交流。金融和办公任务的失败主要在于资源造访;平日糊口和电子商务的失败主要在于信息流;软件工程的失败主要在于器具使用。这对分娩团队的启示是,正确的安全截止设施取决于代理的用途。
扰动贯通性渊博较差。辗转辅导注入在整个测试确立中均导致性能着落幅度最大,贯通性得分在 0.15 至 0.22 之间。在干净任务中看起来尚可接受的模子假想,在抗争性输入下会失效。
为什么这件事面前很艰巨
多智能体 harness 仍是不再只是一个连络问题。它正在成为翌日十二个月内险些整个严肃 agent 居品的基础架构:
编码 agent 仍是是多智能体系统,包括狡计器、检索器、奉行器和审查器。
面向用户的助手也正在酿成多智能体系统,包括分诊、人人模块、升级处理和审计。
运维类 agent 险些自然需要多智能体,因为一朝你战斗多个系统,实质上就在进行协同。
每一次移交,都是信息可能流向不该去的场所的风险点。在单 agent 系统中,信任规模是 agent 的器具调用。而在多 agent 系统中,信任规模酿成了 message bus。是的,咱们正在构建 message bus,却莫得确凿把它动作 message bus 来对待。
翌日该怎么办?
要措置这个问题,要津不单是让模子更强,而是再行假想 harness 自己。
第一,agent 之间不可默许分享完整高下文。每一次信息传递都应该有理解规模:哪些内容不错传、传给谁、能保留多久。面前好多 harness 为了绵薄,平直把完整高下文交给下一个 agent,但这也恰是明锐信息清楚最常见的起首。
第二,安全评测不可只看最终谜底,而要回到完整奉行轨迹。一个 agent 即使给出了正确效力,也可能在经过中造访了不该造访的资源,调用了不该调用的器具,或把明锐信息传给了不该知说念的组件。因此,确凿的安全审计需要逐步查验每一次器具调用、资源造访和 agent 间通讯。
第三,多 agent 系统需要明确的 need-to-know 机制。每个子 agent 只应该获取完成现时任务所必需的信息,而不是默许秉承一说念高下文。更理念念的假想是世界杯(中国),子 agent 先声明我方需要什么信息,再由 harness 或 message bus 判断是否允许传递。